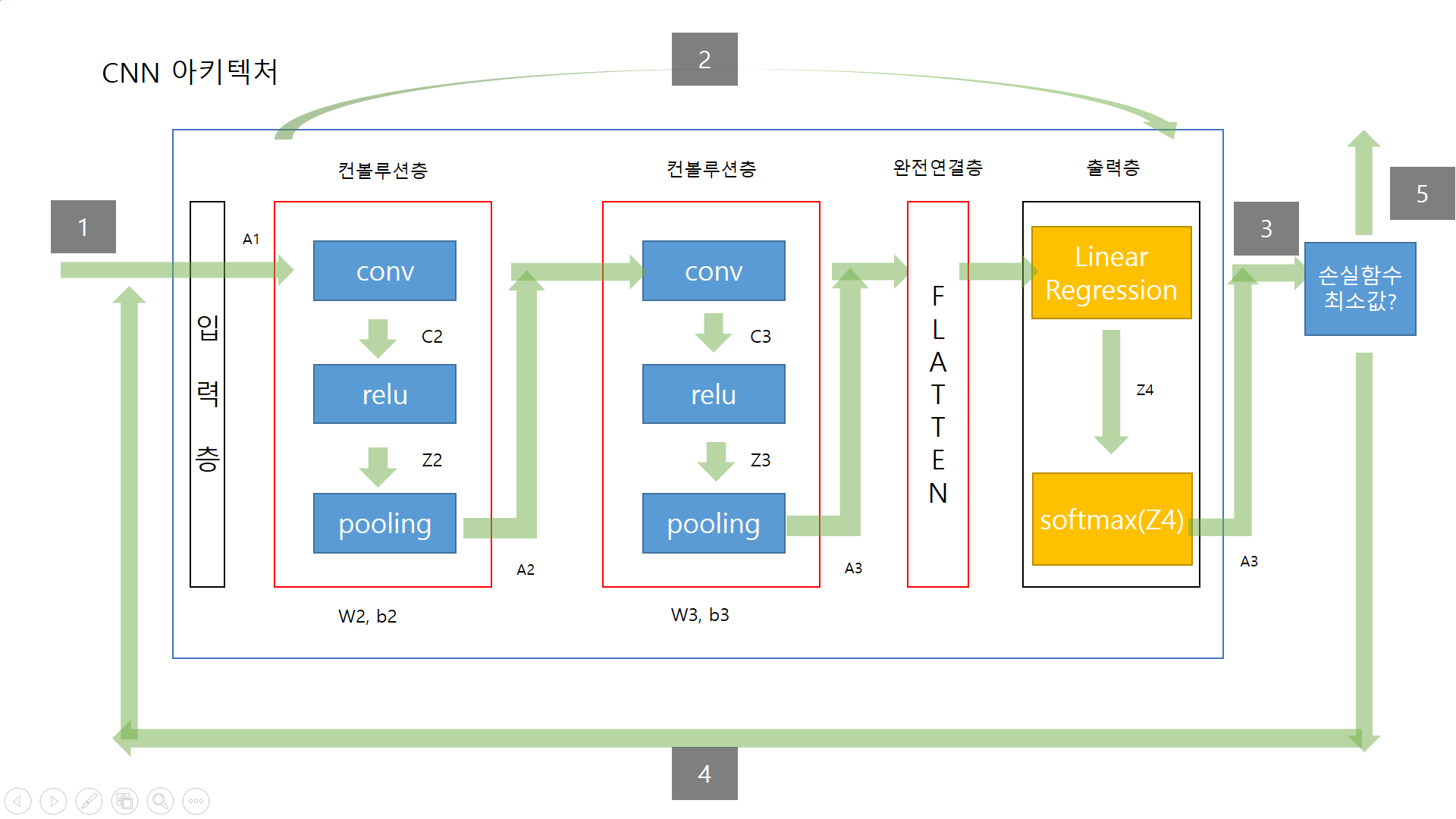
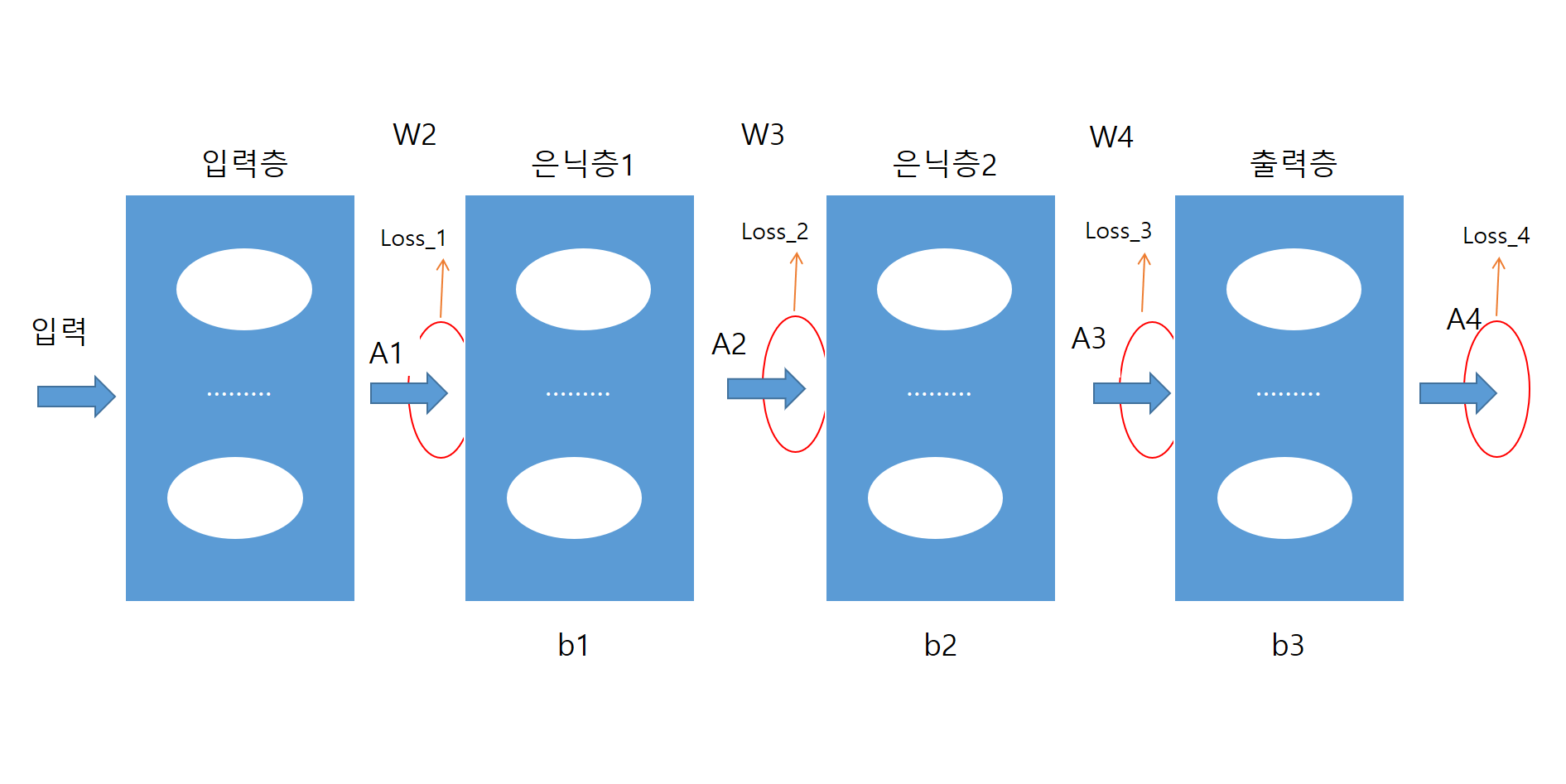
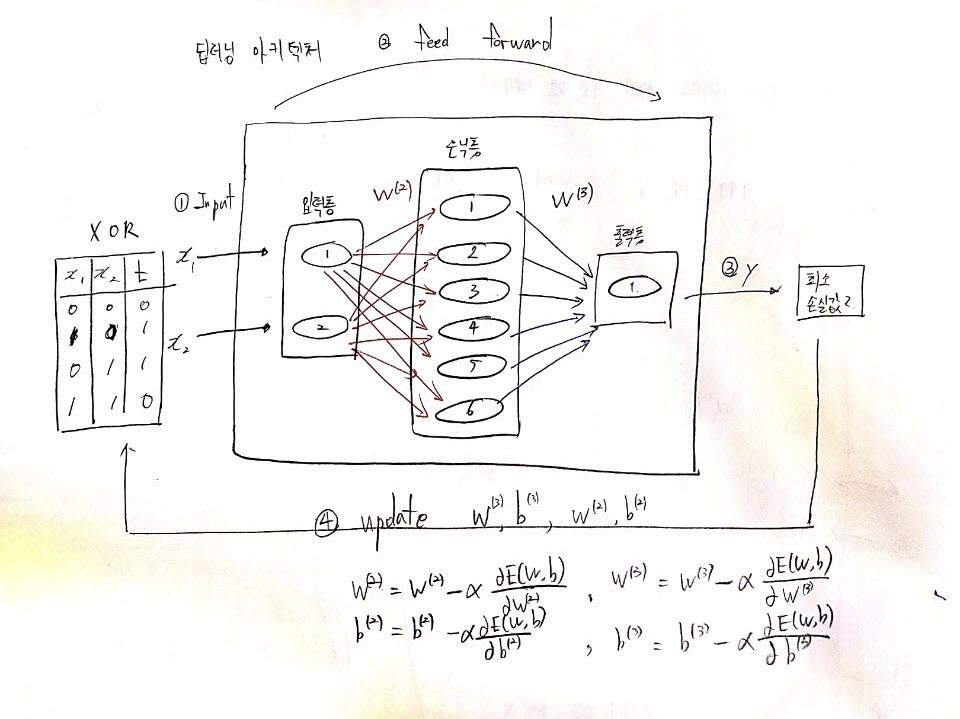
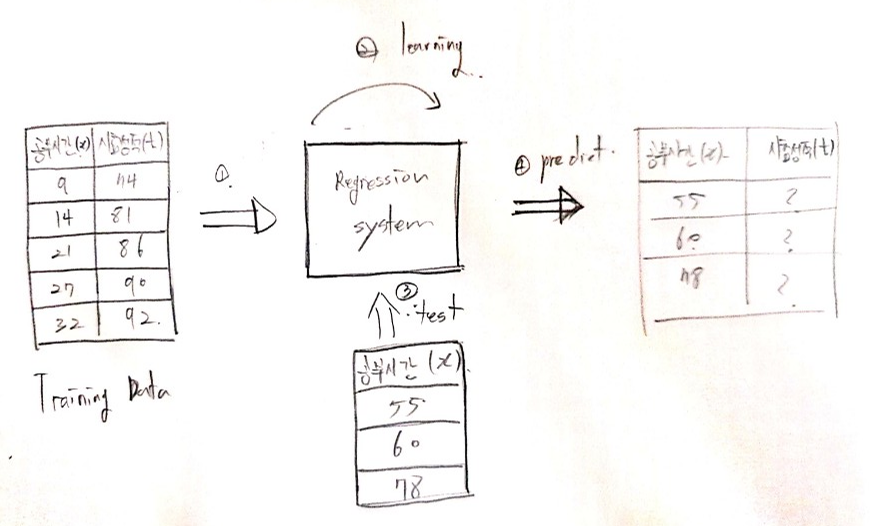
CNN 나만의 정리 1. CNN 1.1 CNN 구조 CNN의 경우 일반적인 신경망과 진행은 비슷하지만, feed forward 부분에서 일반적 신경망에서의 은닉층 부분을 CNN에서는 완전연결층으로 수행한다. 1번 : 입력데이터 x와 t를 insert 2번 : feedforwad 과정 컨볼루션층과 완전연결층을 거쳐 출력 y를 내보낸다 3번 : 출력 y값이 최소값인지 아닌지 판단 4번 : 최소가 아니라면 계속해서 반복 옵티마이저를 사용하여 W, b를 업데이트 5번 : 최소일경우 학습 종료 1.2 컴볼루션층 개요 컨볼루션 층에서는 총 3가지 단계로 순서대로 이루어져 있다. 입력데이터와 필터들과의 컨볼루션 연산을 통해서입력 데이터 특징을 추출하여 특징 맵을 만들고 (conv) 특징맵에서 relu를 통해 필요없는..