딥러닝
1. 딥러닝으로 XOR문제 해결
XOR 문제로 알아보는 딥러닝 아키텍처
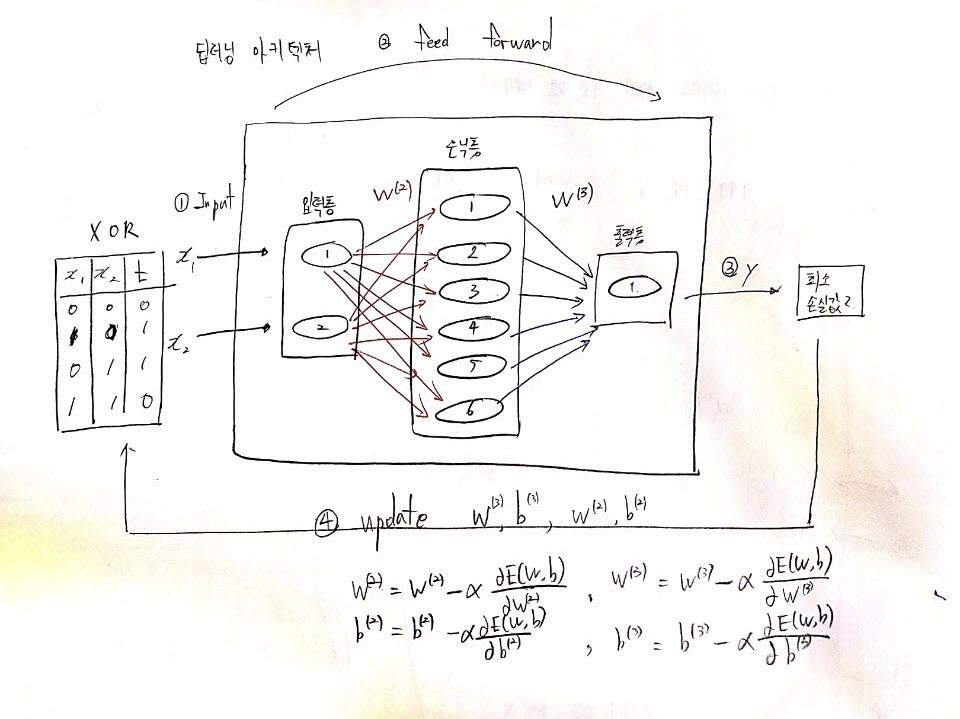
위 그림은 XOR 데이터를 입력으로 하는 딥러닝의 아키텍처를 그린것이다
해당 아키텍처는 입력층 - 은닉층 - 출력층으로 이루어져있고, 은닉층의 경우 여러개의 은닉층을 만들수 있다. 다만 은닉층과 노드 수가 많아지면 학습 속도가 느려지고 정확도에 문제가 발생할수 있기 때문에 적절한 개수의 은닉층과 노드수를 고려하여 구현해야한다.
딥러닝이 한 번 훈련할때 위 1~4번까지 순서대로 반복하는데 아래 상세하게 작성해보겠다.
1번 Input!!
x1, x2의 입력데이터를 입력층에 넣는다.
2번 feed forward
feed forward 과정으로서 각각의 층의 출력이 다음 층의 입력값으로 들어가는 과정이다
입력층의 output은 은닉층의 input으로 가고, 은닉층의 output은 출력층의 input으로 가서 y값을 출력한다.
3번 y값과 t의 비교!!
훈련을 끝마친 출력값 y와 기존의 정답인 t를 비교하면서 둘의 차이가 최소인지를 판단한다.
4번 update
한 번의 훈련이 끝나면 이전의 W, b를 갱신하여 다시 훈련을 진행한다.
이러한 과정을 계속해서 반복하면서 y와 t의 차이를 최소로 만들어주는가중치와 bias값을 찾아낸다
코드 구현
진행 과정
(1) LogicGate 클래스의 init에서 입력데이터(x,t), 가중치, bias 초기화
(2) 훈련 1번 시작
(3) 모든 가중치와 bias를 편미분을 통해 업데이트
(4) 업데이트된 가중치와 bias들로 손실함수값을 구하자
(5) 손실함수를 최소로 만들기 위한 (2)번 과정을 계속해서 반복
(6) 손실함수를 최소로 만드는 가중치들과 bias를 활용하여 test data로 결과를 예측
[1] external function(sigmoid, numerical_derivative)
import numpy as np
# 수치미분 함수
# [3-2] W,b에 대한 편미분값을 구해준다. (업데이트 해주는 함수)
def numerical_derivative(f, x):
delta_x = 1e-4 # 0.0001
grad = np.zeros_like(x)
it = np.nditer(x, flags=['multi_index'], op_flags=['readwrite'])
while not it.finished:
idx = it.multi_index
tmp_val = x[idx]
x[idx] = float(tmp_val) + delta_x
fx1 = f(x) # f(x+delta_x)
x[idx] = tmp_val - delta_x
fx2 = f(x) # f(x-delta_x)
grad[idx] = (fx1 - fx2) / (2*delta_x)
x[idx] = tmp_val
it.iternext()
return grad
# sigmoid 함수 : 출력값이 0 ~ 1사이의 값을 가지는 함수
def sigmoid(x):
return 1 / (1+np.exp(-x))[2]. LogicGate class(init, feed_forward, loss_val)
class LogicGate:
# [1] 처음 훈련이 시작될때 입력데이터와 W, b값들, learning rate를 초기화
def __init__(self, gate_name, xdata, tdata):
self.name = gate_name
# 입력 데이터, 정답 데이터 초기화
self.__xdata = xdata.reshape(4,2) # 4개의 입력데이터 x1, x2 에 대하여 batch 처리 행렬
self.__tdata = tdata.reshape(4,1) # 4개의 입력데이터 x1, x2 에 대한 각각의 계산 값 행렬
# 2층 hidden layer unit : 6개 가정, 가중치 W2, 바이어스 b2 초기화
self.__W2 = np.random.rand(2,6) # weight, 2 X 6 matrix
self.__b2 = np.random.rand(6)
# 3층 output layer unit : 1 개 , 가중치 W3, 바이어스 b3 초기화
self.__W3 = np.random.rand(6,1)
self.__b3 = np.random.rand(1)
# 학습률 learning rate 초기화
self.__learning_rate = 1e-2
print(self.name + " object is created")
# [5] 업데이트된 W, b를 활용하여 딥러닝 한번 훈련 진행한뒤 손실함수값을 return
# feed_forward는 cross-entropy를 활용 cross-entropy의 경우 W,b,x의 변수를 갖는 다변수 함수
def feed_forward(self):
delta = 1e-7 # log 무한대 발산 방지
# 입력층과 은닉층 사이
z2 = np.dot(self.__xdata, self.__W2) + self.__b2 # 은닉층의 선형회귀 값
a2 = sigmoid(z2) # 은닉층의 출력
# 은닉층과 출력층 사이
z3 = np.dot(a2, self.__W3) + self.__b3 # 출력층의 선형회귀 값
y = a3 = sigmoid(z3) # 출력층의 출력
# cross-entropy를 이용하여 손실 함수값 계산
return -np.sum( self.__tdata*np.log(y + delta) + (1-self.__tdata)*np.log((1 - y)+delta ) )
def loss_val(self): # 외부 출력을 위한 손실함수(cross-entropy) 값 계산
delta = 1e-7 # log 무한대 발산 방지
z2 = np.dot(self.__xdata, self.__W2) + self.__b2 # 은닉층의 선형회귀 값
a2 = sigmoid(z2) # 은닉층의 출력
z3 = np.dot(a2, self.__W3) + self.__b3 # 출력층의 선형회귀 값
y = a3 = sigmoid(z3) # 출력층의 출력
# cross-entropy
return -np.sum( self.__tdata*np.log(y + delta) + (1-self.__tdata)*np.log((1 - y)+delta ) )
# 수치미분을 이용하여 손실함수가 최소가 될때 까지 학습하는 함수 (최소를 만들어주는 W, b를 구해내는것)
def train(self):
f = lambda x : self.feed_forward()
print("Initial loss value = ", self.loss_val())
for step in range(10001):
# [2] 훈련시작
# [3-1] 딥러닝을 한번 훈련시킬때마다 가중치들과 bias들을 업데이트 해준다
# learning_rate의 크기에 따라 속도가 차이남 작을수록 느리지만 정확도가 높음
# 입력층 - 은닉층 사이 가중치와 bias를 업데이트 해줌
self.__W2 -= self.__learning_rate * numerical_derivative(f, self.__W2)
self.__b2 -= self.__learning_rate * numerical_derivative(f, self.__b2)
# 은닉층 - 출력층사이의 가중치와 bias를 업데이트 해줌
self.__W3 -= self.__learning_rate * numerical_derivative(f, self.__W3)
self.__b3 -= self.__learning_rate * numerical_derivative(f, self.__b3)
# [4] 400번 훈련할때마다 손실함수를 구하자
if (step % 400 == 0):
print("step = ", step, " , loss value = ", self.loss_val())
# [5] 2번과정을 반복
# [6] query, 즉 미래 값 예측 함수
def predict(self, xdata):
z2 = np.dot(xdata, self.__W2) + self.__b2 # 은닉층의 선형회귀 값
a2 = sigmoid(z2) # 은닉층의 출력
z3 = np.dot(a2, self.__W3) + self.__b3 # 출력층의 선형회귀 값
y = a3 = sigmoid(z3) # 출력층의 출력
if y > 0.5:
result = 1 # True
else:
result = 0 # False
return y, result
# XOR Gate 객체 생성
xdata = np.array([ [0, 0], [0, 1], [1, 0], [1, 1] ])
tdata = np.array([0, 1, 1, 0])
xor_obj = LogicGate("XOR", xdata, tdata)
xor_obj.train()
test_data = np.array([ [0, 0], [0, 1], [1, 0], [1, 1] ])
for data in test_data:
print(xor_obj.predict(data))XOR object is created
Initial loss value = 4.749351783475067
step = 0 , loss value = 4.638791743076451
step = 400 , loss value = 2.7764572456224297
step = 800 , loss value = 2.77169887526281
step = 1200 , loss value = 2.7671431563954325
step = 1600 , loss value = 2.7623125714684957
step = 2000 , loss value = 2.7567135699576775
step = 2400 , loss value = 2.749756870236581
step = 2800 , loss value = 2.740682233279516
step = 3200 , loss value = 2.728490532282401
step = 3600 , loss value = 2.711892185506353
step = 4000 , loss value = 2.689270806545548
step = 4400 , loss value = 2.6586486818432373
step = 4800 , loss value = 2.617700999744083
step = 5200 , loss value = 2.5640523984383283
step = 5600 , loss value = 2.496176417082734
step = 6000 , loss value = 2.4146443059641727
step = 6400 , loss value = 2.3224091696119014
step = 6800 , loss value = 2.2231879784933226
step = 7200 , loss value = 2.119102970397387
step = 7600 , loss value = 2.0094358606452123
step = 8000 , loss value = 1.8911365680932182
step = 8400 , loss value = 1.7608371779401568
step = 8800 , loss value = 1.6175542208038354
step = 9200 , loss value = 1.4642458767266646
step = 9600 , loss value = 1.307006052205737
step = 10000 , loss value = 1.1529864022404333
(array([0.09873157]), 0)
(array([0.75200969]), 1)
(array([0.75029345]), 1)
(array([0.37919475]), 0)'Data Science > 머신러닝' 카테고리의 다른 글
| CNN 나만의 정리 (0) | 2020.09.17 |
|---|---|
| 오차역전파 나만의 정리 (0) | 2020.09.16 |
| 딥러닝 기초 나만의 정리 (0) | 2020.07.08 |
| LSTM으로 IMDB 리뷰 감성 분류하기 (0) | 2020.07.02 |
| Logistic Regression(Classification) 나만의 정리 (0) | 2020.06.28 |
| Linear Regression 나만의 정리 (2) | 2020.06.27 |
| 지도학습과 비지도학습 나만의 정리 (0) | 2020.06.26 |
| 수치미분 나만의 정리 (0) | 2020.06.26 |


