CNN 나만의 정리
1. CNN
1.1 CNN 구조
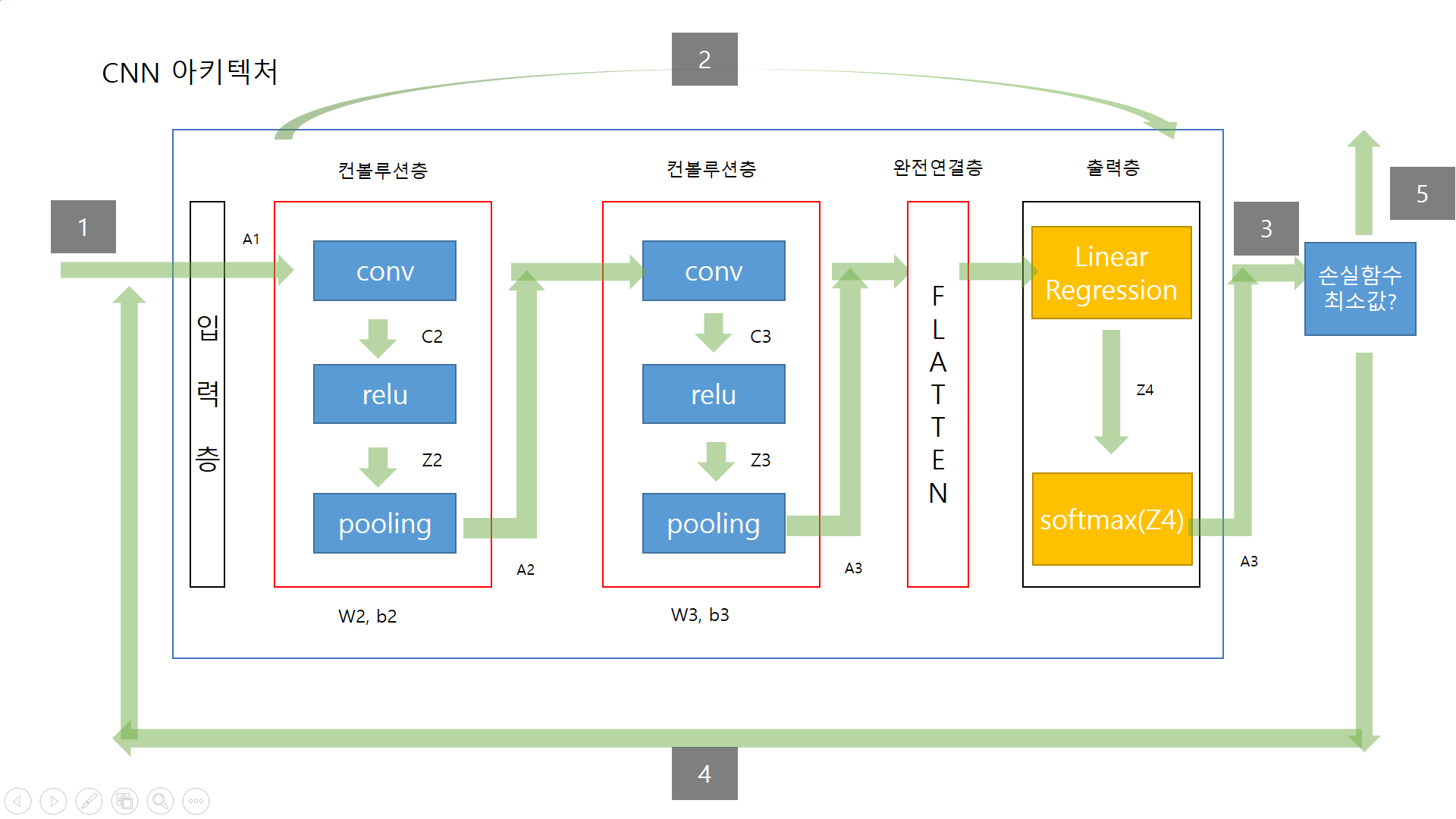
CNN의 경우 일반적인 신경망과 진행은 비슷하지만, feed forward 부분에서 일반적 신경망에서의 은닉층 부분을 CNN에서는 완전연결층으로 수행한다.
1번 : 입력데이터 x와 t를 insert
2번 : feedforwad 과정 컨볼루션층과 완전연결층을 거쳐 출력 y를 내보낸다
3번 : 출력 y값이 최소값인지 아닌지 판단
4번 : 최소가 아니라면 계속해서 반복 옵티마이저를 사용하여 W, b를 업데이트
5번 : 최소일경우 학습 종료
1.2 컴볼루션층 개요
컨볼루션 층에서는 총 3가지 단계로 순서대로 이루어져 있다.
입력데이터와 필터들과의 컨볼루션 연산을 통해서입력 데이터 특징을 추출하여 특징 맵을 만들고 (conv)
특징맵에서 relu를 통해 필요없는 데이터 0으로 초기화한뒤, (relu)
특징맵에서 최대 값을 뽑아서 다음층을 전달하는 역할 (pooling)
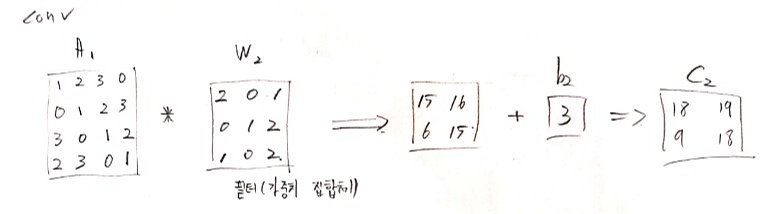
conv(컨볼루션, convolution)
입력데이터와 filter를 컨볼루션 연산을 통해 입력데이터의 특징(feature)을 추출하는 역할
A1 * filter_1 + b2 ===> 입력데이터 A1 특징 추출(C2)
아래는 4 X 4 인 A1에 패딩을 1을 입력과 filter를 컴볼루션 연산을 진행한 과정
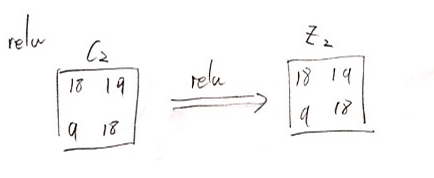
relu (활성화함수)
입력이 0보다 크면 그대로 값을 내보내고, 0보다 작으면 0을출력해줌
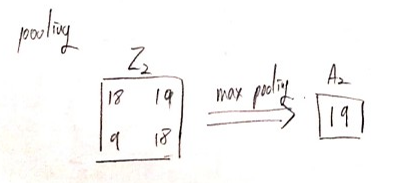
pooling
입력 정보를 최대값, 최소값, 평균값 등으로 압축하여 데이터 연산량을 줄여주는 역할 수행
1.3 완전 연결층
컨볼루션 층의 3차원 출력값을 1차원 벡터로 평탄화 작업 수행하여 일반 신경망 연결처럼 출력층의 모든 노드와 연결시켜주는 역할 수행
1.4 출력층
입력받은 값을 선형회귀를 거쳐 소프트맥스를 통해 0 ~ 1사이의 값을 출력함
소프트맥스 : 출력값의 총합이 항상 1을 만드는 역할
1.5 패딩(padding)
- 패딩이란 컨볼루션 연산을 수행하기 전에 입력 데이터 주변에 특정 값으로 채우는것으로 말하며 컨볼루션 연산을 수행할때 데이터 크기가 줄어드는 단점을 방지하기 위해 사용한다.
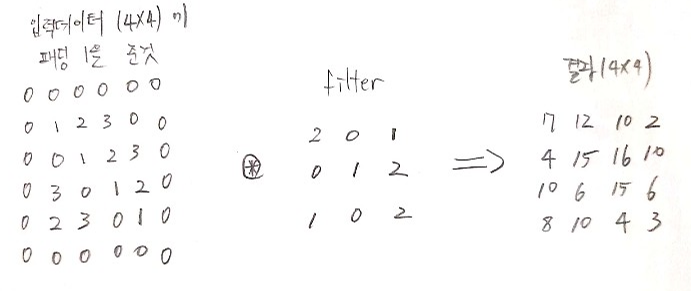
2. Over view - Tensorflow
2.1 conv
tf.nn.conv2d(input, filter, strides, padding, ....)
input : 컨볼루션 연산을 위한 입력데이터이며 [batch, in_height, in_width, in_channels]
예를 들어, 100개의 배치로 묶은 28 x 28 크기의 흑백이미지를 입력으러 넣을경우 [100, 28, 28, 1]로 나타냄
filter : 컨볼루션연산에 적용될 필터 [filter_height, filter_width, in_channels, out_channels] 예를 들어, 필터 크기 3 x 3, 입력채널 1개, 적용되는 필터 개수 32개일경우 filter는 [3, 3, 1, 32]로 나타냄
strides : 컨볼루션 연산을 위해 필터를 이동시키는 간격을 나타냄. 예를 들어 [1, 1, 1, 1]은 컨볼루션 연산을 위해 1칸씩 이동함
padding : 'SAME' 또는 'VALID' 값을 가짐. SAME은 입력값과 같은 크기의 출력이 리턴되고 VALID는 크기가 축소된 결과가 리턴됨
2.2 pooling
tf.nn.max_pool(value, ksize, strides, padding, ...)
value : relu를 통과한 출력결과를 나타내고 pooling의 입력데이터로 들어옴
ksize : ksize는 [1, height, width, 1] 형태로 표시함. [1, 2, 2, 1] 이라면 (2 x 2) 데이터중 가장 큰 값 1개를 찾아서 반환하는 의미
strides : strides가 [1, 2, 2, 1] 일경우 max pooling 적용을 위하 2칸씩 이동하는 것을 의미
padding : max pooling을 수행하기에는 데이터가 부족한 경우에 주변에 0 등으로 채워주는 역할을함
3. 코드 구현
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
import numpy as np
from datetime import datetime # datetime.now() 를 이용하여 학습 경과 시간 측정
# read_data_sets() 를 통해 데이터를 객체형태로 받아오고
# one_hot 옵션을 통해 정답(label) 을 one-hot 인코딩된 형태로 받아옴
mnist = input_data.read_data_sets("MNIST_data/", one_hot=True)
# mnist 데이터 셋은 train, test, validation 3개의 데이터 셋으로 구성되어 있으며.
# num_examples 값을 통해 데이터의 갯수 확인 가능함
# print("\n", mnist.train.num_examples, mnist.test.num_examples, mnist.validation.num_examples)
# 데이터는 784(28x28)개의 픽셀을 가지는 이미지와
# 10(0~9)개 클래스를 가지는 one-hot 인코딩된 레이블(정답)을 가지고 있음
print("\ntrain image shape = ", np.shape(mnist.train.images))
print("train label shape = ", np.shape(mnist.train.labels))
print("test image shape = ", np.shape(mnist.test.images))
print("test lab el shape = ", np.shape(mnist.test.labels))
# Hyper-Parameter
learning_rate = 0.001 # 학습율
epochs = 30 # 반복횟수
batch_size = 100 # 한번에 입력으로 주어지는 MNIST 개수, 100개씩 들어감
# 입력과 정답을 위한 플레이스홀더 정의
X = tf.placeholder(tf.float32, [None, 784])
T = tf.placeholder(tf.float32, [None, 10])
# 입력층의 출력 값. 컨볼루션 연산을 위해 reshape 시킴
A1 = X_img = tf.reshape(X, [-1, 28, 28, 1]) # image 28 X 28 X 1 (black/white)
#### 2. feed forward 부분 ####
# 1번째 컨볼루션 층
# 3X3 크기를 가지는 32개의 필터를 적용
F2 = tf.Variable(tf.random_normal([3, 3, 1, 32], stddev=0.01))
b2 = tf.Variable(tf.constant(0.1, shape=[32]))
# 1번째 컨볼루션 연산을 통해 28 X 28 X1 => 28 X 28 X 32
# 컨볼루션 과정 => (A1 * F2) + b2
C2 = tf.nn.conv2d(A1, F2, strides=[1, 1, 1, 1], padding='SAME')
# relu
Z2 = tf.nn.relu(C2+b2)
# 1번째 max pooling을 통해 Z2 = 28 X 28 X 32 => A2 = 14 X 14 X 32
A2 = P2 = tf.nn.max_pool(Z2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# 2번째 컨볼루션 층
F3 = tf.Variable(tf.random_normal([3, 3, 32, 64], stddev=0.01))
b3 = tf.Variable(tf.constant(0.1, shape=[64]))
# 2번째 컨볼루션 연산을 통해 14 X 14 X 32 => 14 X 14 X 64
C3 = tf.nn.conv2d(A2, F3, strides=[1, 1, 1, 1], padding='SAME')
# relu
Z3 = tf.nn.relu(C3+b3)
# 2번째 max pooling을 통해 14 X 14 X 64 => 7 X 7 X 64
A3 = P3 = tf.nn.max_pool(Z3, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# 3번째 컨볼루션 층
F4 = tf.Variable(tf.random_normal([3, 3, 64, 128], stddev=0.01))
b4 = tf.Variable(tf.constant(0.1, shape=[128]))
# 3번째 컨볼루션 연산을 통해 7 X 7 X 64 => 7 X 7 X 128
C4 = tf.nn.conv2d(A3, F4, strides=[1, 1, 1, 1], padding='SAME')
# relu
Z4 = tf.nn.relu(C4+b4)
# 3번째 max pooling을 통해 7 X 7 X 128 => 4 X 4 X 128
A4 = P4 = tf.nn.max_pool(Z4, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')
# 완전 연결층
# 4X4 크기를 가진 128개의 activation map을 flatten 시킴, 1차원으로 바꿔주는것
A4_flat = P4_flat = tf.reshape(A4, [-1, 128*4*4])
# 출력층
# 2048개 노드와 10의 행렬을 갖는다.
W5 = tf.Variable(tf.random_normal([128*4*4, 10], stddev=0.01))
b5 = tf.Variable(tf.random_normal([10]))
# 출력층 선형회귀 값 Z5, 즉 softmax 에 들어가는 입력 값
Z5 = logits = tf.matmul(A4_flat, W5) + b5 # 선형회귀 값 Z5
y = A5 = tf.nn.softmax(Z5)
# 손실함수와 optimizer
loss = tf.reduce_mean( tf.nn.softmax_cross_entropy_with_logits_v2(logits=Z5, labels=T) )
optimizer = tf.train.AdamOptimizer(learning_rate)
train = optimizer.minimize(loss)
# batch_size X 10 데이터에 대해 argmax를 통해 행단위로 비교함
predicted_val = tf.equal( tf.argmax(A5, 1), tf.argmax(T, 1))
# batch_size X 10 의 True, False 를 1 또는 0 으로 변환
accuracy = tf.reduce_mean(tf.cast(predicted_val, dtype=tf.float32))
# CNN - 노드 / 연산실행
with tf.Session() as sess:
sess.run(tf.global_variables_initializer()) # 변수 노드(tf.Variable) 초기화
start_time = datetime.now()
for i in range(epochs): # 30 번 반복수행
total_batch = int(mnist.train.num_examples / batch_size) # 55,000 / 100
for step in range(total_batch):
batch_x_data, batch_t_data = mnist.train.next_batch(batch_size)
loss_val, _ = sess.run([loss, train], feed_dict={X: batch_x_data, T: batch_t_data})
if step % 100 == 0:
print("epochs = ", i, ", step = ", step, ", loss_val = ", loss_val)
end_time = datetime.now()
print("\nelapsed time = ", end_time - start_time)
# Accuracy 확인
test_x_data = mnist.test.images # 10000 X 784
test_t_data = mnist.test.labels # 10000 X 10
accuracy_val = sess.run(accuracy, feed_dict={X: test_x_data, T: test_t_data})
print("\nAccuracy = ", accuracy_val)epochs = 0 , step = 0 , loss_val = 2.7652454
epochs = 0 , step = 100 , loss_val = 1.647176
....
epochs = 29 , step = 400 , loss_val = 5.019285e-06
epochs = 29 , step = 500 , loss_val = 0.01970235
elapsed time = 0:28:08.779115'Data Science > 머신러닝' 카테고리의 다른 글
| 오차역전파 나만의 정리 (0) | 2020.09.16 |
|---|---|
| 딥러닝 기초 나만의 정리 2 (0) | 2020.09.16 |
| 딥러닝 기초 나만의 정리 (0) | 2020.07.08 |
| LSTM으로 IMDB 리뷰 감성 분류하기 (0) | 2020.07.02 |
| Logistic Regression(Classification) 나만의 정리 (0) | 2020.06.28 |
| Linear Regression 나만의 정리 (2) | 2020.06.27 |
| 지도학습과 비지도학습 나만의 정리 (0) | 2020.06.26 |
| 수치미분 나만의 정리 (0) | 2020.06.26 |