4장 머신러닝의 기본요소
3장에서는 3개의 예시를 통해 분류와 회귀에 대해 학습했습니다. 이 장에서는 딥러닝 문제에 도전하고 해결하기 위한 개념을 정립해나가겠습니다.
4.1 머신러닝의 네가지 분류
4.1.1 지도 학습
지도학습은 가장 흔한 경우입니다. 샘플 데이터가 주어지면 알고있는 타깃에 입력데이터를 매핑하면서 학습합니다. 지도학습의 대부분은 분류와 회귀로 구성되지만 몇몇 변종들도 존재합니다.
4.1.2 비지도 학습
비지도 학습의 경우 어떤 타깃도 사용하지 않고 입력데이터의 흥미로운 변화를 찾습니다. 데이터 시각화, 데이터 압축, 데이터 노이즈 제거 등 데이터에 있는 상관관계를 찾아내어 이용합니다.
4.1.3 자기 지도 학습
자기 지도 학습(self-supervised learning)은 지도학습의 특별한 경우로서 지도 학습이지만 사람이 만든 레이블을 사용하지 않습니다. 즉 학습과정에서 사람이 개입하지 않고 보통 경험적 알고리즘(heuristic algorithm)을 사용해서 타깃을 생성해냅니다.
4.1.4 강화학습
강화학습(rainforcement learning)에서 에이전트(agent)는 환경에 대한 정보를 받아 보상을 최대화하는 행동을 선택하도록 학습됩니다. 예를 들면 강화학습으로 훈련된 신경망은 게임 화면을 입력으로 받고 게임 점수를 최대화하기 위한 게임내의 행동을 출력할 수 있습니다.
4.2 머신러닝 모델 평가
훈련데이터의 성능은 훈련이 진행될수록 항상 증가됩니다. 반면 검증데이터로 평가할때 정확도가 줄어든다면 이 경우에 일반화가 안됐다고 한다
머신러닝의 목표는 처음 본 데이터에서 잘 작동하는 일반화 된 모델을 얻는 것이다. 그래서 과대적합을 최소화하고 일반화를 최대화하는것이 머신러닝 모델설계의 주요 목표다
4.2.1 훈련, 검증, 테스트 세트
- 모델을 구현할때 데이터를 항상 훈련, 검증, 테스트 3개의 세트로 나눔
- 검증세트에서 모델의 성능을 평가하며 튜닝을 계속해서 할 경우 검증 세트로 훈련시키지 않더라도 간접적으로 모델에 영향을 미치게 되고 검증세트에 과대적합이 될 수도있다. 이 현상의 핵심은
정보누설(information leak)이라고 한다. 결국 최종적으로 검증 데이터에 맞추어 최적화 했기 때문에 모델의 일반화 성능을 왜곡시킴 - 데이터가 적을 때는 몇가지 고급 기법을 사용하자. 대표적으로 단순 홀드아웃 검증(hold-out validation), K-겹 교차 검증(K-fold cross-validation), 셔플링(shuffling)을 활용한 반복 교차 검증이 있음
단순 홀드아웃검증
데이터의 일정량을 테스트세트로 떼어놓는다.
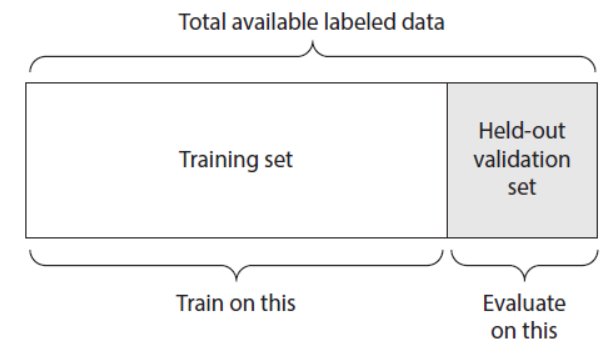
Training set으로 훈련하고 held-out validation set으로 검증하자!!
held-out_validation_set = data[:100] #검증 세트 만듦
Training_set = data[100:] #훈련 세트 만듦단순 홀드 아웃검증의 단점
데이터가 적을때 샘플이 너무 적어 전체 데이터를 통계적으로 대표하지 못할 수 있음
random으로 데이터를 나누었을 때 모델 성능이 달라질수도 있음
K-겹 교차겸증
이 방식은 3장에서 진행했음
K = 3이라고 가정했을때, 전체 데이터를 동일한 크기를 가진 3개로 분할한다.
각 분할된 3개의 데이터에서 2개는 훈련시키고, 1개는 평가합니다.
최종점수는 이렇게 얻은 3개의 점수의 평균을 구합니다.
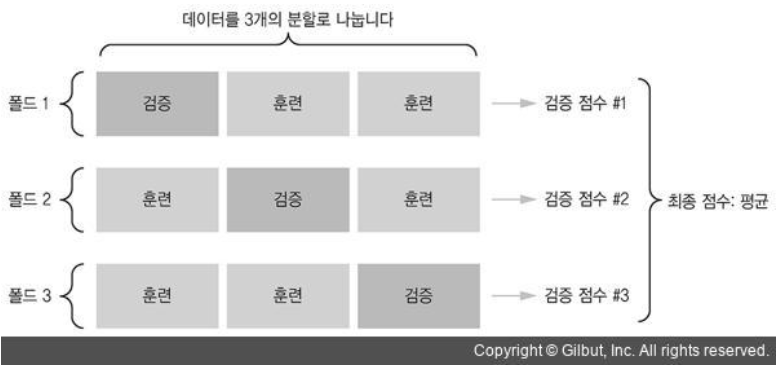
코드구현
# K-겹 교차 검증 구현 예
k = 3
num_validation_samples = len(data) // k
np.random.shuffle(data)
validation_scores = []
for fold in range(k):
#검증 데이터 부분을 선택함
validation_data = data[num_validation_samples * fold:
num_validation_samples * (fold + 1)]
#남은 데이터를 훈련 데이터로 사용
training_data = data[:num_validation_samples * fold] +
data[num_validation_samples * (fold + 1):]
model = get_model() # 훈련되지 않은 새로운 모델 만듬
model.train(training_data)
validation_score = model.evaluate(validation_data)
validation_scores.append(validation_score)
validation_score = np.average(validation_scores) #검증 점수: K개 폴드의 검증 점수 평균
model = get_model() # 테스트 데이터를 제외한 전체 데이터로 최종 모델을 훈련
model.train(data)
test_score = model.evaluate(test_data)셔플링을 사용한 반복 K-겹 교차검증
이 방법은 K-겹 교차 검증을 여러반 적용하되 K개의 분할로 나누기 전에 매번 데이터를 무작위로 섞는다.
결국 P번 섞었을때, P x K개의 모델을 훈련하므로 비용이 매우 많이 든다.
4.2.2 기억해야 할 것
1. 대표성이 있는 데이터
훈련세트와 테스트세트가 주어진 데이터에 대한 대표성이 있어야함. 예를 들면 1~ 9의 숫자 데이터가 있을때 훈련세트에는 17이 존재하고 테스트세트에는 89만 존재하면 안됨. 그래서 데이터를 분류하기 전에 무작위로 섞는것이 일반적이다.
2. 시간의 방향
과거로부터 미래를 예측할때는 무작위로 섞으면 절대 안됨 !! 이렇게 하면 미래의 정보가 누설된다. 이런 문제에서는 훈련세트에 있는 데이터보다 테스트 세트의 데이터가 더 미래의 것이어야 한다!!
3. 데이터 중복
훈련세트와 검증세트에 데이터 중복이 있을경우, 훈련데이터의 일부로 검증을 하는 최악의 경우가 된다. 절대 중복되지 않게 데이터를 준비하자!!
4.3 데이터 전처리, 특성 공학, 특성 학습
신경망에 입력데이터와 타깃 데이터를 주입하기 전에 항상 주의해야한다!!
4.3.1 신경망을 위한 데이터 전처리
데이터 전처리의 목적은 원본 데이터를 신경망에 적용하기 쉽도록 하는것. 벡터화, 정규화, 누락된 값다루기, 특성추출 등이 포함된다.
벡터화
신경망에 모든 입력과 타깃은 부동 소수로 이루어진 텐서 or 정수로 이루어진 텐서여야 한다. 사운드, 이미지, 텍스트 등 처리해야할 무엇이든지 우선 텐서로 변환해야한다. 이 단계를 데이터 벡터화 라고 한다.
이전에 2개의 텍스트 분류 문제에서 텍스트를 정수리스트로 변환한뒤, 원-핫 인코딩을 사용해서 float32 타입의 데이터로 이루어진 텐서로 바꾸었다
값 정규화
이미지 분류 문제에서 이미지 데이터를 크레이스케일 인코딩인 0 ~ 255 사이의 정수로 인코딩 했다. 이 데이터를 네트워크에 주입하기 전에 float32 타입으로 변경하고 255나누어 최종적으로 0 ~ 1 사이의 부동소수 값으로 만들었다.
주택 가격을 예측하기 위한 데이터도 제각각이었고, 범위가 매우 컸다. 그래서 각 특성을 정규화하여 평균이 0이고 표준편차가 1이 되도록 만들었다.
일반적으로 비교적 큰 값이나 균일하지 않은 데이터를 신경망에 주입하는건 위험하다.
일반적으로 대부분의 값이 0 ~ 1사이여야한다.(필수)
균일해야하다. 즉 모든 특성이 대체로 비슷한 범위를 가져야함(필수)
각 특성별로 평균이 0이되고 표준편차가 1이 되도록 정규화한다(권장)
# 넘파이 배열일경우 하는 방법은간단함 x -= x.mean(axis=0) x /= x.std(axis=0)
누락된 값 다루기
이따금 데이터에 값이 누락되는 경우가 있다. 이럴땐 누락됨을 의미하기 위해 0을 입력하자.
누락됨을 나타내지 않으면 네트워크에서는 누락됨을 알수없다.
4.3.2 특성 공학
4.4 과대적합곽 과소적합
모델의 성능이 몇번의 에포크 후에 최고치에 다다랐다가 감소된다면, 모델이 금방 훈련데이터에 과대적합(overfitting)되기 시작하는것임
훈련데이터의 손실이 낮아질수록 테스트 데이터의 손실도 낮아질경우 이 모델은 과소적합(underfitting) 되었다고 말하는데, 모델의 성능이 계속 발전될 여지가 있음을 의미한다.
4.4.1 네트워크 크기 축소
과대적합을 막는 가장 단순한 방법은 모델의 크기, 즉 모델에 있는 학습 파라미터의 수를 줄이는것이다.
파라미터의 수는 층의 수와 각 층의 유닛 수에 결정된다. 모델을 만들기 위해 과대적합, 과소적합이 발생되지 않는 마법같은 공식은 존재하지 없다. 데이터에 알맞는 모델을 찾기위해선 아래와 같은 순서를 따르자.
- 적절한 모델의 크기를 찾기위해 비교적 적은 수의 층과 파라미터로 시작한다.
- 그 다음 검증 손실이 감소되기 시작할 때까지 층이나 유닛의수를 늘리는것이다.
3장의 문제인 리뷰 분류 문제를 활용하여 validation loss의 변화를 알아봅시다.
# 2-1 original 모델 만들기
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
# 2-2 small 모델 만들기
model = models.Sequential()
model.add(layers.Dense(6, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(6, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
# 2-3 large 모델만들기
model = models.Sequential()
model.add(layers.Dense(1024, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(1024, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))은닉층의 갯수를 기존의 16개에서 6개, 1024개의 모델을 만들어서 검증손실을 비교해보자
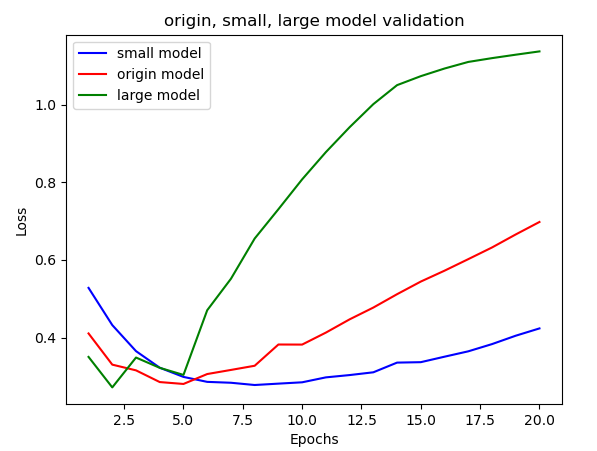
위 그래프를 보면 과대적합이 시작되는 에포크의 차례를 알수있습니다.
| small model(파랑) | original model(빨강) | large model(초록) |
|---|---|---|
| 8~9번째 | 5~6번째 | 2~3번째 |
네트워크가 가장 큰 초록의 경우 2번의 훈련만에 바로 과대적합을 진행하고, 네트워크가 가장 작은 파랑의 경우 8번째의 훈련에서 과대적합이 시작되는걸 볼수있다.
용량이 많은 네트워크일수록 훈련 데이터를 빠르게 모델링하기 때문에 과대적합에 더 민감할 수 밖에 없다.(결국 훈련과 검증손실에 큰 차이를 보인다.)
4.4.2 가중치 규제 추가
간단한 모델이 복잡한 모델보다 과대적합될 가능성이 낮다. 네트워크의 복잡도를 낮춰 과대적합을 최소화하는것이다. 그러므르 가중치가 작은값을 가지도록 규제하는것이 가중치규제(weight regularization) 라고 한다.
가중치를 규제하기 위해 연관된 비용을 추가합니다.
L1 규제 : 가중치의 절댓값이 비례하는 비용을 추가
L2 규제 : 가중치의 제곱에 비례하는 비용을 추가]. 가중치 감쇠라고도 불립니다.(가중치가 0.001이라면 0.001 X 0.001을 추가하여 가중치를 감소시킵니다)
4.4.3 드롭아웃 추가
드롭아웃은 신경망에 가장 효과적이고 널리 사용되는 방법 중 하나다. 네트워크층에 드롭아웃을 적용하면 훈련하는동안 무작위로 층의 일부를 제외시킨다.
층에서 일부를 제외시킨다는것은 층에서 우연한 패턴을 깨뜨리는 결과를 만들어낸다. 결국 비슷한 패턴들끼리 계속 학습을 진행하면서 정확도를 높여나갈것이다.
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
model.add(layers.Dropout(0.5)) # 층과 층 사이에 드롭아웃을 추가한다.
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dropout(0.5))
model.add(layers.Dense(1, activation='sigmoid'))과대적합을 방지하기 위해 널리 사용되는 방법
[1] 훈련 데이터가 많아야한다.
[2] 네트워크의 용량을 감소시킨다.
[3] 가중치 규제를 추가한다.
[4] 드롭아웃을 추가한다.
'Data Science > 딥러닝' 카테고리의 다른 글
| 6장 텍스트 시퀀스를 딥러닝1 (0) | 2020.11.08 |
|---|---|
| 5장 컴퓨터 비전을 위한 딥러닝1 (0) | 2020.10.29 |
| 3장 신경망 시작하기2 (0) | 2020.10.26 |
| 5장 컴퓨터 비전을 위한 딥러닝2 (0) | 2020.09.23 |
| 3장 신경망 시작하기1 (0) | 2020.08.31 |
| 2장 시작하기 전에: 신경망의 수학적 구성요소 (0) | 2020.08.31 |