2. 시작하기 전에: 신경망의 수학적 구성요소
2.1 신경망과의 첫 만남
딥러닝의 아주 기초적인 데이터셋인 MNIST를 사용한 예제를 풀어보겠다.
MNIST는 딥러닝계의 "hello world"라고 생각될정도로 기초중의 기초 예제다
MNIST 데이터셋 : 6만개의 훈련 이미지와 1만개의 테스트 이미지로 구성
이번 예제의 경우 케라스를 완벽하게 이해하지 않아도 된다.
이번 예제는 케라스의 전체적인 구성과 코드의 흐름만 파악하도록 하자
# 2-1 케라스에서 MNIST 데이터셋 적제하기
from keras.datasets import mnist
from keras.utils import to_categorical
(train_images, train_labels),(test_images, test_labels) = mnist.load_data()MNIST 데이터셋은 넘파이 배열형태로 케라스에 이미 포함되어있음
# 2-2 이미지 데이터 준비하기
train_images = train_images.reshape((60000, 28 * 28))
train_images = train_images.astype('float32') / 255
test_images = test_images.reshape((10000, 28 * 28))
test_images = test_images.astype('float32') / 255훈련을 시작하기전 데이터를 네트워크에 맞는 크기로 바꾸고, 모든 값을 0과 1 사이로 스케일을 조정한다.
예를 들어 앞서 우리의 훈련이미지는 [0, 255] 사이의 값인 unit8타입의 (60000, 28, 28) 크기의 배열로 저장되어있다.
이 데이터를 0과 1사이의 값을 가지는 float32 타입의 (60000, 28*28) 크기인 데이터로 변환
# 2-3 신경망 구조
from keras import models
from keras import layers
network = models.Sequential()
network.add(layers.Dense(512, activation='relu', input_shape=(28 * 28,)))
network.add(layers.Dense(10, activation='softmax'))신경망의 핵심 구성요소는 데이터 처리 필터인 layer(층)이라고 할수있다.
신경망층인 Dence층 2개가 연속되어, 두번째 층은 10개의 확률점수가 들어있는 배열을 반환하는
softmax 층입니다.
# 2-4 컴파일 단계
network.compile(optimizer='rmsprop', loss='categorical_crossentropy', metrics=['accuracy'])신경망이 훈련을 마치기 위해 컴파일 단계에서 3가지가 더 필요
손실함수(loss fuction) : 훈련데이터에서 신경망의 성능을 측정하는방법으로 네트워크가 옳은 방향으로 학습될수있도록 도와줌
옵티마이저(optimizer) : 입력된 데이터와 손실함수를 기반으로 네트워크를 업데이트하는 메커니즘
훈련과 테스트 과정을 모니터링할 지표 : 여기에서는 정확도만 고려하겠습니다.
# 2-5 레이블 준비하기
from keras.utils import to_categorical
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)이부분은 3장에서 자세히할 예정
# 코드를 훈련하고 실행한 결과
network.fit(train_images, train_labels, epochs=5, batch_size=128)
test_loss, test_acc = network.evaluate(test_images, test_labels)
print('test_acc: ', test_acc)fit 메서드를 호출하여 훈련데이터에 모델을 학습시킴
네트워크가 128개 샘플씩 미니배치로 훈련데이터를 다섯번 반복합니다.
각 반복마다 네트워크가 배체에서 손실에 대한 가중치의 그래디언트를 계산하고 가중치응 업데이트해 나갑니다.
1번의 에포크동안 469번의 그래디언트 업데이트를 수행합니다. (6만개의 훈련데이터를 128개씩 배치를 나누면 469개의 배치가 만들어진다.)
60000/60000 [==============================] - 3s 45us/step - loss: 0.2549 - acc: 0.9264
Epoch 2/5
60000/60000 [==============================] - 4s 61us/step - loss: 0.1046 - acc: 0.9683
Epoch 3/5
60000/60000 [==============================] - 3s 46us/step - loss: 0.0688 - acc: 0.9793
Epoch 4/5
60000/60000 [==============================] - 3s 45us/step - loss: 0.0490 - acc: 0.9850
Epoch 5/5
60000/60000 [==============================] - 4s 62us/step - loss: 0.0377 - acc: 0.9883
10000/10000 [==============================] - 0s 26us/step
test_acc: 0.97892.2 신경망을 위한 데이터 표현
이전 예제에서 텐서(tensor) 라 부르는 다차원 넘파이 배열에 데이터를 저장하는것부터 시작했다.
그렇다면 텐서란 무엇일까 ??
텐서는 데이터를 위한 컨테이너(container)이다. 거의 항상 수치형 데이터를 다루므로 숫자를 위한 컨테이너입니다. 이러한 텐서는 임의의 차원 개수를 가지는 행렬의 일반화된 모습입니다.
2.2.1 스칼라(0D 텐서)
하나의 숫자만 담고 있는 텐서를 스칼라(scalar) 또는 0차원 텐서 라고 부릅니다.
2.2.2 벡터 (1D 텐서)
숫자의 배열을 벡터(vector) 또는 1D텐서라고 부릅니다. 1D 텐서는 딱 하나의 축(axis)을 가집니다
2.2.3 행렬 (2D 텐서)
백터의 배열이 행렬 또는 2D텐서입니다. 행렬에서 2개의 축이 있습니다. (보통 행과 열이라고 부릅니다.)
import numpy as np
x = np.array([[5,7,3,4,2], [2,5,3,2,64], [46,3,4,1,2]])
>> 22.2.4 3D텐서와 고차원 텐서
이런 행렬들을 하나의 새로운 배열로 합치면 숫자가 채워진 직육면체 형태로 해석할 수 있는 3D텐서가 만들어집니다.
import numpy as np
x = np.array([[[5,7,3,4,2], [2,5,3,2,64], [46,3,4,1,2]],
[[5,7,3,4,2], [2,5,3,2,64], [46,3,4,1,2]],
[[5,7,3,4,2], [2,5,3,2,64], [46,3,4,1,2]]])
>> 32.2.5 핵심속성
- 축의 개수(차원) : 예를 들어 3D 텐서에는 3개의 축이, 2D 텐서에는 2개의 축이 있습니다. 해당 축은 ndim속성에 저장되있습니다.
- 크기 : 위 예시로 나온 3D텐서의 크기는 (3, 3, 5)입니다. (갯수, 행, 렬) 형태
- 데이터 타입 : dtype 속성에 저장되 있습니다. 텐서의 타입은 float32, uint8, float64 등이 될수 있습니다.
2.2.6 넘파이로 텐서 조작하기
배열에 있는 특정 원소들을 슬라이싱(slicing)으로 조작할 수 있습니다.
6만개의 이미지 데이터를 가진 train_images을 슬라이싱해보자
my_slice = train_images[10:100, :, :]
print(my_slice.shape)
>> (90, 28, 28)행렬이 각각 28개인 배열을 가진 데이터를 90개 추출해낼수 있습니다.
2.2.7 배치 데이터
일반적으로 딥러닝에서 사용하는 모든 데이터 텐서의 첫 번째 축은 샘플 축(samplae axis)입니다.
딥러닝 모델은 한 번에 전체 데이터 셋을 처리하지 않고, 데이터를 작은 배치(batch)로 나눈다.
# 첫 번째 배치 (샘플축 or 배치축 or 배치차원)
batch = train_images[:128]
# 두 번째 배치
batch = train_images[128:256]
# n 번째 배치
batch = train_images[128*n : 128*(n+1)]2.2.8 텐서의 실제 사례
우리가 사용할 데이터는 대부분 다음 중 하나에 속할 것입니다.
- 백터 데이터 : (samples, features) 크기의 2D텐서
- 시계열 데이터 또는 시퀀스 데이터 : (samples, timesteps, features) 크기의 3D 텐서
- 이미지 : (samples, height, width, channels) 또는 (samples, channels, height, width) 크기의 4D 텐서
- 동영상 : (samples, frames, height, width, channels) 또는 (samples, frames, channels, height, width) 크기의 5D 텐서
2.2.9 백터 데이터
이런 데이터셋의 경우 2D 텐서로 인코딩될 것입니다.
첫번째 축은 샘플축이고 두번째 축은 특성축 입니다.
- 나이, 소득, 우편번호로 구성된 인구통계데이터. 각 사람은 3개의 데이터로 구성되고 10만명이 포함된 전체 데이터셋은 (100000, 3) 크기의 텐서에 저장될 수 있습니다.
2.2.10 시계열 데이터 또는 시퀀스 데이터
데이터에서 시간이 중요할 때는 시간 축을 포함하여 3D 텐서로 저장됩니다.
- 주식 가격 데이터셋 : 1분마다 현재 주식 가격, 지난 1분 동안에 최고 가격과 최소가격 총 3개의 데이터로 구성함. 하루의 거래 시간이 390분이고 250일치의 데이터를 저장한다면 (250, 390, 3) 크기의 3D텐서로 저장될수 있다.
2.2.11 이미지 데이터
흑백이미지의 경우 차원(축) 크기를 1로 저장하고 컬러이미지는 3으로 저장합니다
- 흑백 이미지에 대한 128개 이미지 배치는 (128, 256, 256, 1)로 저장 될수 있습니다.
- 컬러 이미지에 대한 128개 이미지 배치는 (128, 256, 256, 3)로 저장 될수 있습니다.
2.2.12 비디오 데이터
비디오는 프레임의 연속이고 각 프레임은 하나의 컬리이미지 이므로, 1D 텐서만 추가하면 됩니다.
2.3 신경망의 톱니바퀴 : 텐서연산
텐서의 연산에 대해 알아보자
2.3.1 연소별 연산
원소별 연산은 텐서에 있는 각 원소에 독립적으로 연산함을 의미합니다. 넘파이 배열 연산의 경우 넘파이 시스템에 설치된 BLAS 구현에 복잡한 일들을 위임합니다. BLAS에서 relu연산, 덧셈, 곱셈 등의 연산을 합니다
2.3.2 브로브캐스팅(broadcasting)
크기가 다른 두 텐서를 더할경우 작은 텐서가 큰 텐서의 크기에 맞추어 브로브캐스팅 됩니다.
- 큰 텐서의 ndim에 맞도록 작은 텐서에 축이 추가됩니다.
- 작은 텐서가 새 축을 따라서 큰 텐서의 크기에 맞도록 반복합니다.
2.3.3 텐서 접곰
텐서곱셈이라고도 부르는 점ㄱ보연산은 가장 널리 사용되는 유용한 텐서연산입니다.
아래 그림처럼 (a, b)의 크기를 같는 x와 (b, c)의 크기를 같는 y를 점곱할경우
x º y = (a, b) º (b, c) = (a, c) 가 된다.
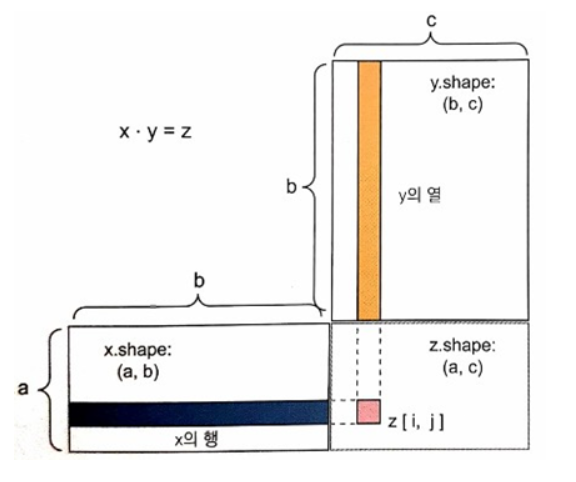
2.3.4 텐서 크기 변환
텐서 크기 변환이란 텐서의 크기를 특정 크기에 맞게 열과 행을 재배열 한다는 뜻입니다.
>>> x = np.array([[0,1],
[2,3],
[3,4]])
>>> x.shape
(3, 2)
>>> x = x.reshape((6,1)) # (3, 2)의 크기를 (6, 1)로 변환
>>> x
[[0]
[1]
[2]
[3]
[3]
[4]]
>>> x = np.transpose(x) # transpose는 전치입니다. 행과 열을 바꾸는것을 의미합니다.
>>> x.shape
(1, 6)2.3.5 텐서 연산의 기하학적 해석
텐서 연산이 조작하는 텐서의 내용은 기하학적 공간에 있는 좌표 포인트로 해석 될 수 있기 때문에 모든 텐서 연산은 기하학적 해석이 가능합니다.
A = [0.5, 1]와 B = [1, 0.25]가 있을때 두 벡터의 덧셈은 아래 처럼 나타낼수 있습니다.
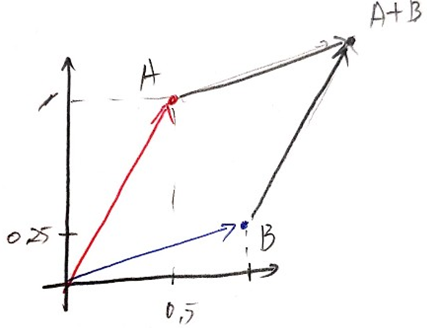
2.4 신경망의 엔진: 그래디언트 기반 최적화
신경망의 각 층은 입력데이터를 다음과 같이 변환합니다.
y = Wx + b (W: 가중치, X : 입력데이터, b: bias) 이와 같은 표현을 코드로 나타내면 아래와 같습니다.
output = relu(dot(W, input) + b)이 식에서 W와 b는 각 층의 속성처럼 볼수 있습니다. 이런 가중치(W)에는 훈련 데이터를 신경망에 노출시켜서 학습된 정보가 담겨있습니다.
아래는 훈련 반복 루프 단계를 보여줍니다. 이 과정을 반복하면서 손실값, 즉 예측 y_pred와 타깃 y의 오차가 작아지도록 훈련을 진행합니다. 매 훈련을 진행할때마다 가중치가 점진적으로 조정되면서 y_pred와 차이가 적은 y의 W를 찾아냅니다.
- 훈련 샘플 x와 이에 상응하는 타깃 y의 배치를 추출합니다.
- x를 사용하여 네트워크를 실행하고, 예측 y_pred를 구합니다
- y_pred와 y의 차이를 측정하여 이 배치에 대한 네트워크의 손실을 계산합니다.
- 배치에 대한 손실이 감소되도록 네트워크의 모든 가중치를 업데이트 합니다.
이 부분은 가볍게 정리했고, 다른 카테고리의 선형회귀 부분에서 더 자세하게 다뤘습니다.
https://gold-jae.tistory.com/8?category=926769
2.4.1 변화율이란 ?
이 부분 역시 위 링크에 더 자세하게 다뤘습니다.
'Data Science > 딥러닝' 카테고리의 다른 글
| 6장 텍스트 시퀀스를 딥러닝1 (0) | 2020.11.08 |
|---|---|
| 5장 컴퓨터 비전을 위한 딥러닝1 (0) | 2020.10.29 |
| 4장 머신러닝의 기본요소 (0) | 2020.10.28 |
| 3장 신경망 시작하기2 (0) | 2020.10.26 |
| 5장 컴퓨터 비전을 위한 딥러닝2 (0) | 2020.09.23 |
| 3장 신경망 시작하기1 (0) | 2020.08.31 |