5장 컴퓨터 비전을 위한 딥러닝1
이번 장에는 컨브넷(convnet)이라고 불리는 합성곱 신경망(convolutional neural network)에 대해 학습하고 MNIST 숫자 이미지 분류 예시를 활용하여 컨브넷을 사용해보자
5.1 합성곱 신경망 소개
다음 코드는 기본적인 컨브넷의 모습이다. Conv2D와 MaxPooling2D 층을 쌓아올렸습니다.
model = models.Sequential()
# 컨볼루션 층
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
# 완전연결층
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax')) # 0~9까지의 숫자 분류를 위해 최종출력을 10으로 한다.
>>> model.summary()# model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
# 컨볼루션 층
conv2d_1 (Conv2D) (None, 26, 26, 32) 320
_________________________________________________________________
max_pooling2d_1 (MaxPooling2 (None, 13, 13, 32) 0
_________________________________________________________________
conv2d_2 (Conv2D) (None, 11, 11, 64) 18496
_________________________________________________________________
max_pooling2d_2 (MaxPooling2 (None, 5, 5, 64) 0
_________________________________________________________________
conv2d_3 (Conv2D) (None, 3, 3, 64) 36928
_________________________________________________________________
# 완전연결층
flatten_1 (Flatten) (None, 576) 0
_________________________________________________________________
dense_1 (Dense) (None, 64) 36928
_________________________________________________________________
dense_2 (Dense) (None, 10) 650
=================================================================코드와 결과를 비교하면서 컨볼루션층과 완전연결층에 대해 학습해보자
컨볼루션층
input_shape=(28, 28, 1) : 컨브넷은 (image_height, image_width, image_channels) 크기의 입력텐서를 사용한다는 점이 중요하다. 이 예제는 MNIST 이미지 포멧인 (28, 28, 1) 크기의 입력을 처리하도록 했다.
Conv2D와 MaxPooling2D의 출력은 (height, width, channels) 크기의 3D텐서로 출력한다. 결과를 보다시피 높이와 너비 차원은 네트워크기 깊어질수록 작아지는 경향이 있다.
완전연결 층
컨볼루션 층의 마지막층의 출력텐서(3, 3, 64)를 완전연결층에 주입합니다. 컨볼루션 층의 경우 3D텐서 출력을 하기 때문에 3D텐서를 1D텐서로 펼쳐야 한다. 그래서 Flatten를 통해 펼치고 Dense층을 통해 학습을 마무리 하면 됩니다.
완전연결층으로 주입될때 3 x 3 x 64 = 576 크기로 벡터가 펼쳐진후 Dense층으로 주입됩니다.
최종코드
from keras import layers
from keras import models
from keras.datasets import mnist
from keras.utils import to_categorical
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(layers.MaxPooling2D((2, 2)))
#컨볼루션층
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
# 완전연결층
model.add(layers.Flatten())
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(10, activation='softmax'))
(train_images, train_labels), (test_images, test_labels) = mnist.load_data()
train_images = train_images.reshape((60000, 28, 28, 1))
train_images = train_images.astype('float32') / 255
test_images = test_images.reshape((10000, 28, 28, 1))
test_images = test_images.astype('float32') / 255
train_labels = to_categorical(train_labels)
test_labels = to_categorical(test_labels)
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
model.fit(train_images, train_labels, epochs=5, batch_size=64)
test_loss, test_acc = model.evaluate(test_images, test_labels)
>>> test_acc
0.99262장의 완전 연결 네트워크는 97.8%의 정확도를 얻었지만, 기본적인 컨브넷은 99.2%의 정확도를 얻었습니다.
더 높은 이유는 Conv2D와 MaxPooling2D 층의 역할때문입니다. 이 두개가 어떤 역할을 하는지 알아보자
5.1.1 합성곱 연산(Conv2D)
Dense 층은 입력 특성 공간에 있는 전역패턴을 학습하지만, 합성곱 층은 지역패턴을 학습합니다. 위 예시의 MNIST의 경우 3 x 3크기의 필터링을 통해 학습을 진행했다.
이 핵심 특성은 컨브넷의 두가지 성질을제공합니다.
- 학습된 패턴은 평행 이동불변성을 가집니다. 컨브넷이 왼쪽 위 모서리의 패턴을 학습했다면 오른쪽 아래에서도 이 패턴을 인식할수 있습니다. 적은 수의 훈련 샘플을 사용해서 일반화 능력을 가진 표현을 학습할 수 있습니다
- 컨브넷은 패턴읙 공간적 계층구조를 학습할수 있습니다. 컨브넷은 매우 복잡하고 추상적인 시각적 개념을 효과적으로 학습할 수 있습니다.
합성곱연산은 특성맵이라고 부르는 3D 텐서에서 적용되는데, 이 텐서는 2개의 축(높이와 너비, 깊이)으로 구성된다.
높이와 너비는 이미지의 크기에 따라 결정되고, 깊이는 RGB, 흑백에 따라 결정된다.
| RGB 이미지 | 흑백 이미지 | |
|---|---|---|
| 깊이 | 3 | 1 |
MNIST 예제를 보면 합성곱 연산층은 (28, 28, 1)로 입력을 받아 (26, 26, 32)의 특성맵을 출력한다. 즉 입력에 대해 32개의 필터를 적용하는것. 32개의 출력채널에 26 X 26크기의 배열 값을 가진다고 생각하면됨.
# 첫번째 합성곱 : (3, 3, 1) 크기의 필터를 32개 적용((3,3)은 패치, 1은 필터)
model.add(layers.Conv2D(32, (3, 3), activation='relu', input_shape=(28, 28, 1)))
model.add(layers.MaxPooling2D((2, 2)))
# 두번째 합성곱 : (3, 3, 32) 크기의 필터를 64개 적용
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))합성곱은 핵심적인 2개의 파라미터로 정의됨
[1] 입력으로부터 뽑아낼 패치의 크기 : 일반적으로 3 X 3 또는 5 X 5 크기를 사용한다.
[2] 특성 맵의 출력 깊이 : 합성곱으로 계산할 필터의 수. 이 예에서는 깊이 32로 시작해서 64로 끝남
경계문제와 패딩 이해하기
앞선 예에서 28 x 28 크기의 입력이 26 x 26크기가 되었습니다. 이는 3 x 3의 패치가 중앙을 맞춰 형성할수 있는 타일은 26개이기 때문입니다.
입력과 같은 크기의 출력을 하고싶은경우 패딩(padding)을 사용하면된다.
5.1.2 최대 풀링 연산
특성맵의 크기가 MaxPooling2D 층마다 절반으로 줄어든다. 특성 맵을 다운 샘플링 하는것이 최대 풀링의 역할
다운샘플링을 사용하는 이유는 처리할 특성 맵의 가중치 개수를 줄이기 위함이다. 다운샘플링을 안하고 학습을 진행할경우 특성의 공간적 계층 구조를 정확히 파악하지 않아 정확한 특징을 가진 특성맵을 만들지 못하고, 최종 특성맵에는 굉장히 많은 원소가 담겨있어서 심각한 오류가 생긴다.
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
conv2d_1 (Conv2D) (None, 26, 26, 32) 320
_________________________________________________________________
conv2d_2 (Conv2D) (None, 24, 24, 64) 18496
_________________________________________________________________
conv2d_3 (Conv2D) (None, 22, 22, 64) 36928 최대풀링이 없을경우 최종특성맵은 22 x 22 x 64 = 30976개의 원소를 가진다.
# 2 x 2를 사용하여 특성 맵을 절반크기로 다운 샘플링하여 특성맵의 가중치를 줄여나가자
model.add(layers.MaxPooling2D((2, 2)))5.2 소규모 데이터셋에서 밑바닥부터 컨브넷 훈련하기
이번 포스트는 소규모 데이터셋을 사용하여 처음부터 새로운 모델을 훈련시켜보자.
강아지 2천장, 고양이 2천장의 이미지를 사용용하여 모델을 만드는데, 과대적합을 줄이기 위해 데이터증식, 사전 훈련된 네트워크로 특성을 추출, 사전 훈련된 네트워크를 세밀하게 튜닝 을 해보면서 과대적합을 줄이고 높은 정확도를 얻어보도록하자.
과대적합(overfitting) : 과대적합은 모델이 훈련데이터에 너무 잘 맞지만 일반성이 떨어진다는 의미, 너무 훈련데이터에 맞추어져 있기 때문에 테스트데이터의 다양한 변수에는 대응하기 힘들어짐
5.2.1 작은 데이터셋 문제에서 딥러닝의 타당성
딥러닝은 데이터가 많을때만 작동한다는 말을 이따금 듣는다. 하지만 많은 샘플이 의미하는것은 상대적인것이다. 모델이 작고 규제가 잘 되어있으며 간단한 작업이라면 수백개의 샘플로도 충분히 할수 있습니다.
5.2.2 데이터 내려받기
kaggle에서 Dogs vs Cats dataset을 다운받습니다 해당 원본데이터셋을 여기에서 내려 받을 수 있다.
이 데이터셋은 2만 5천개의 강아지와 고양이 이미지를 담고 있으며, 해당 데이터에서 각각 훈련용 1000개, 검증용 500개, 테스트 500개를 복사합니다.
5.2.3 네트워크 구성하기
이번 모델은 150 x 150 크기의 입력으로 시작해서 flatten 전까지 7 x 7크기의 특성맵으로 줄어든다.
특성맵의 깊이는 네트워크에서 점진적으로 증가하지만 특성맵의 크기는 감소하고, 만약 입력의 크기와 출력의크기를 같게하고싶다면 padding을 주어 같게할수 있다.
컨브넷 구조
# 5-5 컨브넷 만들기 - 3층 구조
# 컨볼루션 층
# 1. 150 x 150 크기의 컬러 이미지를 입력으로하고, 패치는 3x3으로 한다
model.add(layers.Conv2D(32, (3, 3), activation='relu',input_shape=(150, 150, 3)))
# 2. 이미지의 크기가 150 -> 148로 줄어들고, 32개의 필터를 적용한다.
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
# 3. 3개층의 결과 7 x 7 크기의 특성맵을 출력
# 완전 연결층
model.add(layers.Flatten())
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))모델 훈련
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])binary_crossentropy : 강아지 or 고양이 분류 문제라 binary_crossentropy를 사용
RMSprop 옵티마이저 : 값이 무한히 커지는것을 방지하기 위한 방법. RMSprop은 지수 이동 평균을 이용한방법인데, 지수 이동평균이란 최근 값이 더 잘반영하기 위해 최근 값과 이전 값에 각각 다른 가중치를 주어 계산하는 방법
5.2.4 데이터 전처리
데이터는 네트워크에 주입되기전에 부동 소수 타입의 텐서로 적절하게 전처리 되어 있어야합니다. (텐서내 정수 크기가 작아야 학습이 잘됨)
- 사진파일을 읽습니다.
- JPEG콘텐츠를 RGB 픽셀 값으로 디코딩합니다.
- 부동소수타입의 텐서로 변환합니다.
- 픽셀값(0~255사이의 값)의 스케일을 [0,1]사이로 조정합니다.
이런 과정을 케라스에서 자동으로 처리하는 유틸리티가 존재합니다.
ImageDataGenerator 사용해서 이미지 파일을 전처리된 텐서로 자동 변환
from keras.preprocessing.image import ImageDataGenerator
# 모든 이미지를 1/255로 스케일을 조정합니다
train_datagen = ImageDataGenerator(rescale=1./255)
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=20,
class_mode='binary')train_generator와 validation_generator을 통해 이미지를 150 x 150크기로 바꾸고 각 배치에는 20개의 샘플을 담도록합니다.
배치 제너레이터를 사용하여 모델 훈련하기
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=30,
validation_data=validation_generator,
validation_steps=50)
model.save('cats_and_dogs_small_1.h5')한번의 epochs 마다 steps_per_epoch=100번의 경사하강법 단계를 실행함. (30번의 epochs를 실행)
여기서는 20개의 샘플이 하나의 배치이므로 2000개의 샘플을 모두 처리할때까지 100개의 배치를 뽑을것이다.
아래 학습 결과인 훈련과 검증정확도 그리고 훈련과 검증손실 그래프를 보여줍니다.
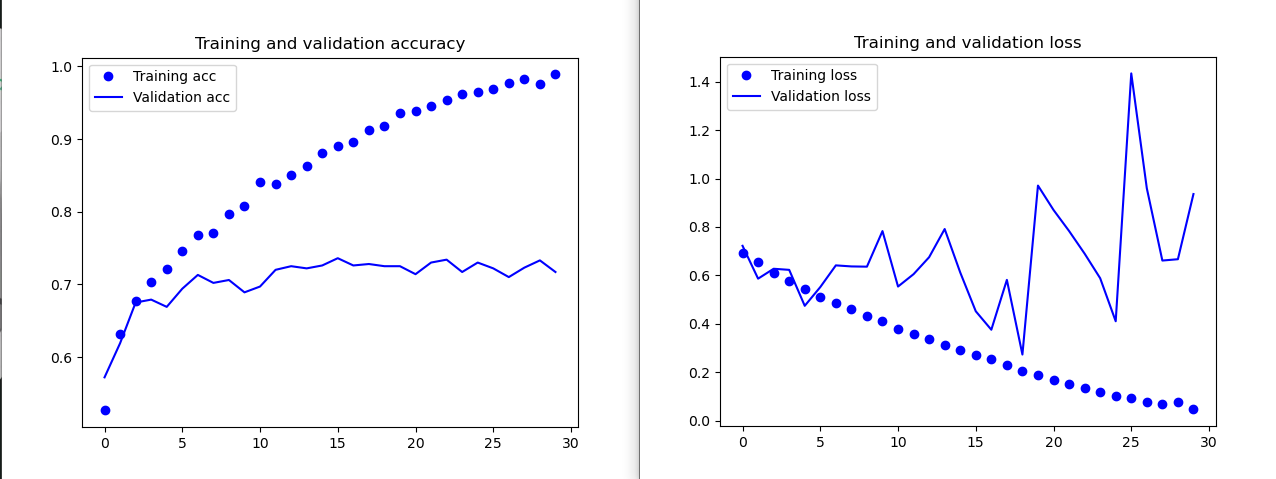
훈련정확도가 시간이 지남에 따라 30번의 epoch끝에 100%에 도달합니다. 반면에 검증 정확도는 70~72%에서 멈추었습니다.
훈련 손실은 거의 0에 도달했지만 검증 손실은 5번의 에포크만에 최소값에 다다른 이후 더 이상 감소하지 않았습니다.
비교적 샘플데이터(2000개)가 적기 때문에 과대적합이 가장 중요한 문제입니다.
다음 포스트는 딥러닝에서 이미지를 다룰때 일반적으로 사용되는 새로운 방법인 데이터 증식에 대해 알아보겠습니다.
5.2.5 데이터 증식 사용하기
데이터 증식은 기존 훈련 샘플로부터 더 많은 훈련 데이터를 생성하는 방법입니다.
ImageDataGenerator를 사용하여 데이터 증식 설정하기
datagen = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
fill_mode='nearest')[1] rotation_range : 랜덤하게 사진을 회전시킬 각도 범위(0 ~ 180 사이)
[2] width_shift_range : 사진을 수평으로 랜덤하게 평행이동
[3] height_shift_range : 사진을 수직으로 랜덤하게 평행이동
[4] shear_range : 랜덤하게 shearing transformation을 적용할 각도 범위
[5] zoom_range : 랜덤하게 사진을 확대할 범위
[6] horizontal_flip : 랜덤하게 이미지를 수평으로 뒤집음
[7] fill_mode : 회전이나 가로이동으로 인해 새롭게 생성해야 할 픽셀을 채울 전략
드롭아웃을 포함
데이터 증식을 사용하면 입력 데이터가 두 번 주입되지 않는다. 하지만 적은수의 이미지를 증식했기 때문에 여전히 입력데이터들 사이에 상호 연관성이 크다. 그래서 과대적합을 억제하기 위해 완전 연결 분류기 직기전에 Dropout층을 추가하자!!
model.add(layers.Dropout(0.5))최종코드
# 데이터 증식
from keras import layers
from keras import models
from keras import optimizers
from keras.preprocessing.image import ImageDataGenerator
import matplotlib.pyplot as plt
from keras.preprocessing import image
train_dir = './datasets/cats_and_dogs_small/train'
validation_dir = './datasets/cats_and_dogs_small/validation'
model = models.Sequential()
model.add(layers.Conv2D(32, (3, 3), activation='relu',
input_shape=(150, 150, 3)))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(64, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Conv2D(128, (3, 3), activation='relu'))
model.add(layers.MaxPooling2D((2, 2)))
model.add(layers.Flatten())
model.add(layers.Dropout(0.5)) # 드롭아웃 추가
model.add(layers.Dense(512, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
model.compile(loss='binary_crossentropy',
optimizer=optimizers.RMSprop(lr=1e-4),
metrics=['acc'])
# 훈련데이터 증식을 위한
train_datagen = ImageDataGenerator(
rescale=1./255,
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True)
# 검증 데이터는 증식되어서는 안 됩니다!
test_datagen = ImageDataGenerator(rescale=1./255)
train_generator = train_datagen.flow_from_directory(
train_dir,
target_size=(150, 150),
batch_size=32,
class_mode='binary')
validation_generator = test_datagen.flow_from_directory(
validation_dir,
target_size=(150, 150),
batch_size=32,
class_mode='binary')
history = model.fit_generator(
train_generator,
steps_per_epoch=100,
epochs=20,
validation_data=validation_generator,
validation_steps=50)
model.save('cats_and_dogs_small_2.h5')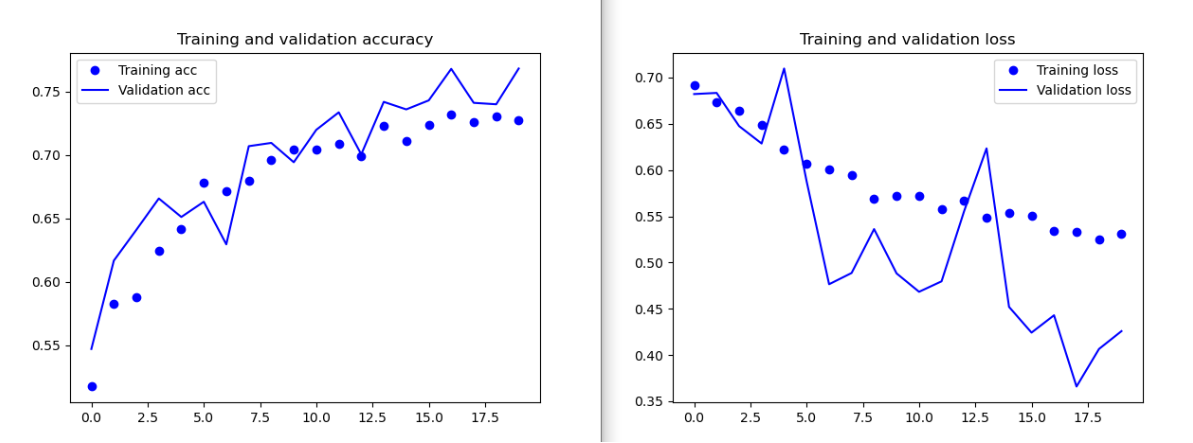
위 코드는 상대적으로 오래걸려 20번의 학습만 진행했지만, 더 많은 훈련을 진행할 경우 82%까지의 정확도를 달성할수 있습니다. 앞서 규제하지 않은 모델에 비해 15% 정도 향상되었다.
여기서 더 정확도를 높이기 위해선 사전에 훈련된 모델을 사용해야한다.
'Data Science > 딥러닝' 카테고리의 다른 글
| 6장 텍스트 시퀀스를 딥러닝1 (0) | 2020.11.08 |
|---|---|
| 4장 머신러닝의 기본요소 (0) | 2020.10.28 |
| 3장 신경망 시작하기2 (0) | 2020.10.26 |
| 5장 컴퓨터 비전을 위한 딥러닝2 (0) | 2020.09.23 |
| 3장 신경망 시작하기1 (0) | 2020.08.31 |
| 2장 시작하기 전에: 신경망의 수학적 구성요소 (0) | 2020.08.31 |